Reddit, a popular online discussion site, has a running joke: would rather fight a horse-sized duck or 100 duck-sized horses? This bizarre question has surprising relevance to Office 365, because while Microsoft customers often worry about the threat of a widespread large outage (the horse-sized duck), they’re actually getting beat up by a larger number of smaller, less damaging but still annoying outages (the group of duck-sized horses). There are deeper issues here that warrant a closer look in order to understand what the real risks are, and what you can do about them.
The SLA Problem
Microsoft is justly proud of its financially-backed 99.9% SLA for Office 365. They’ve invested a huge amount of talent and treasure in building a robust worldwide service, with more built-in redundancy and availability features than any on-premises customer can hope to provide its users. The devil is in the details, though; that 99.9% SLA is an aggregate across all users of the service worldwide. As Tony Redmond has written, with such a large subscriber base, an Office 365 outage that affects 3.5 million users for 12 hours would only reduce the quarterly SLA by a tiny amount. Of course, those 3.5 million users might not be comforted by this fact if they’re unable to work because of an outage. Using Microsoft’s own SLA as a yardstick just isn’t very helpful given that even a widespread or long-lasting outage might not make a real dent in their SLA number.
The Workload Problem
Back in the days of BPOS, Exchange Online was the only real usable cloud workload in Microsoft’s arsenal. Those days are long gone; Exchange has been joined by Skype, SharePoint, OneDrive, and a host of new services (Teams, Power BI, Planner, Sway, the Office web productivity applications, OneNote, and so on). Adding these services is Microsoft’s way of trying to make Office 365 more sticky, and to help organizations justify the cost and effort of adopting Office 365 by giving them more service power per dollar.
The problem occurs when people start using these additional services. Office 365 MVP Alan Byrne makes this point well when he points out that getting a few dollars off your Power BI licenses due to an outage won’t make up for the cost of not being able to use Power BI to make business decisions (or, worse, the cost imposed by making a bad decision!)
It’s almost always the case that newly added services lag behind the “big 3” of Exchange, Skype, and SharePoint in reliability and continuity, merely because the workloads are less mature (and also, possibly, because the operational and support processes for running them are less mature as well). The takeaway here is that when your business relies on one of these secondary workloads, you may not be able to depend on either the same service quality or SLA that the big 3 offer.
Bring On The Duck-Sized Horses
Recently, Office 365 customers in various locations have suffered through a number of small outages. None of these outages got truly widespread press coverage, in part because they were generally localized to specific regions. As Office 365 is more widely deployed into region-specific data centers, we’ll probably see this trend continue, which is both good and bad—good in that outages may become smaller and more localized, but bad because if an outage occurs near you, you’ll be out of luck. Think of the cellular phone system—if your local cell goes down, you can’t use your phone until you travel to another cell’s coverage area.
A sampling of recent outages includes these:
There might have been others, too—it’s not critical to have an exact count, as that doesn’t diminish the point that a small outage can be just as bad for you as a large one.
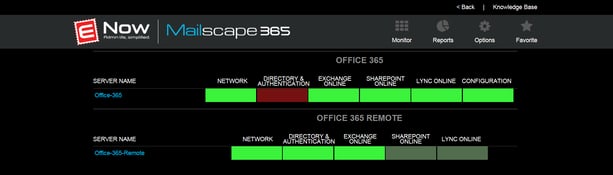
Your Personal Outage Detector
Mailscape 365 helps you protect against and respond to duck and horse attacks. Because we don’t depend on any single test to tell you whether your Office 365 service is healthy or not, outages that only affect one of the workloads (or part of a single workload) still trigger alerts to tell you what’s going on. For example, our user experience monitoring probes independently test MAPI and Exchange Web Services access to Office 365 from your user locations—so if Outlook Anywhere breaks but EWS is up, or vice versa, you’ll know, and you can plan accordingly to help affected clients (perhaps giving them all Macs, since the Mac version of Outlook is EWS-only… just kidding, put down the torches and pitchforks). Our synthetic monitoring tests do the same thing that users do, using the same operations that Microsoft’s own client applications do,
Because we allow you to monitor user experience from all your locations, we give you full visibility into outages no matter how large or small they are. Because we monitor multiple workloads (and parts of those workloads), you get rapid, actionable insight into exactly which services are broken, what the impact is to your users, and what you need to do to let them keep working.
Of course, many Office 365 problems aren’t because of anything on Microsoft’s end—problems with your own hybrid servers (including dirsync and AD FS) or network connectivity can keep your users from being productive. We monitor and report on those components too, so whether an outage has its roots in Microsoft’s data center or yours, you can see the horse-ducks approaching and take the necessary action.
What This All Means
The major reason that organizations adopt Office 365 is to take advantage of Microsoft’s promise of better service quality at a lower cost than they can provide for themselves. Microsoft overall does an excellent job of delivering on this promise, but with such a complex infrastructure underlying their global Office 365 deployment, you need to have an independent view of whether the service is available and ready for your users. We can help—download the Mailscape 365 trial today and see!
We live in a complex, interconnected world. In particular, Azure and Office 365 are extremely complex systems. Pinpointing the cause of this sort of outage reminds me of the lengthy investigative process that takes place after a commercial airplane crashes. While it might be easy to quickly find a credible root cause, the initial reports often lack depth, so it’s usually worth waiting for a detailed analysis to highlight exactly what happened, why it happened, and how it can be prevented. However, having that detailed analysis is only useful after the fact—in the moment, you need an immediate read on whether the services you depend on are working or not, and Mailscape 365 gives you that in a clear, immediately digestible format. (And if you think that’s cool, wait until you see what we’re working on next….)