Google beating Microsoft in mobile apps? Maybe for consumer, but not for business

The nice people at SurveyMonkey sent me a note about their blog post of 20 April titled “Office 365...


Exchange Online running on Microsoft’s Office 365 cloud platform operates more than 100,000 servers to support some 60 million mailboxes. At least, that’s the best-guess estimate based on information provided by Microsoft at the Exchange Conference 2014, data in their most recent financial reports, and consultant analysis.Even if the figures are a little skewed, there’s no doubt that Exchange Online is a massive distributed environment that supports thousands of companies worldwide. Office 365 continues growing strongly and some estimates predict that more mailboxes will be hosted in the cloud than are on on-premises servers by the end of 2017.
Exchange Online running on Microsoft’s Office 365 cloud platform operates more than 100,000 servers to support some 60 million mailboxes.
Without a solid methodology for monitoring such an environment, Microsoft would have no chance of achieving the Office 365 Service Level Performance (SLA) guarantee of 99.9% uptime. Given the success Microsoft has had in building and operating Office 365, it is fair to ask whether any lessons learned from this experience can be applied to on-premises deployments?
This document first describe some of the more important aspects of Office 365 operations (as reported by Microsoft). It then offers four specific areas of focus of value to on-premises Exchange deployments and examines the steps that administrators can take to improve their operating environment. The discussion is deliberately kept at a high level as the intention is to provoke discussion about how operations are conducted today and how benefit might be gained by applying some or all of the lessons learned from Office 365.

Of course, the team that designed, built, and operates Office 365 enjoys many advantages that help it in its task. The Exchange engineering team is part of the same group that runs Office 365 and engineers are directly responsible for supporting the features they develop for “the service.” Other Microsoft engineering assets are available too, such as the talented engineers who work on Windows. In addition, Microsoft Research has helped to develop the machine learning capabilities that underpin new features such as People View and Clutter. Finally, the strong financial success that Microsoft has enjoyed over many years has enabled its balance sheet to support the investment of many billions of dollars required to build out a worldwide datacenter fabric that hosts cloud services like Office 365 and Azure today.
But all the assets in the world do not provide a simple answer to the problem of how to build and operate software at such massive scale. A lot of heavy lifting has been done to develop Exchange to the point where it can be run at the economic price point required for a competitive cloud service. This work has happened over the last decade and includes areas such as storage (to make Exchange run well on low-cost JBOD disks), automation, and protocol simplification.
Much of the output from this engineering work is found in the on-premises version of Exchange too.
Much of the output from this engineering work is found in the on-premises version of Exchange too. For example, Exchange 2013 introduces Managed Availability, a feature specifically developed to provide servers with an automatic “self-healing” capability necessary to avoid manual interventions to fix problems. It’s easy for a human to fix a problem with a failing Exchange server if only two or three servers are in use; it is quite another matter if the problem affects servers within a pool of several thousand Exchange mailbox servers, which could be the case in any of Microsoft’s Office 365 datacenters.
Much of the output from this engineering work is found in the on-premises version of Exchange too.
As it built out the Office 365 program, Microsoft paid a lot of attention to the lessons learned from its previous Business Productivity Online Services (BPOS) cloud offering. BPOS suffered because it used an older generation of software products that were designed for enterprise deployment rather than the cloud. It also suffered because of a lack of automation and workflow capabilities.
Today’s Office 365 uses a sophisticated workflow engine called “Central Admin” (CA) that is capable of handling more than 50 million workflow tasks per month. The idea is to automate common tasks as much as possible so as to achieve a reliable and robust throughput of actions across the system. Tasks are expressed to CA in the form of scripted workflows in either C# or PowerShell. CA executes tasks on schedule to perform actions such as server deployment, database rebalancing within a Database Availability Group, and so on. More complex tasks such as the addition of new capacity to the service still needs some human intervention and intelligence, but the application of a structured model and great attention to detail has enabled Microsoft to reduce the time necessary to complete even very complex tasks down from weeks to days.
Office 365 servers are built to a standardized design. This does not mean that exactly the same components are used every time as this would be impossible in an industry where components change frequently. However, it does mean that a server will have the same general characteristics (CPU, disk, memory) and that software is installed in the same way on all servers of a specific type. Low-cost components such as disks are used in order to be able to provide users with features such as 100GB mailboxes while still being market competitive. Using JBOD disks brings a certain risk of a higher failure rate and indeed, across Office 365, hard disk failures are the most common event of the more than ten thousand hardware events that are handled monthly.
Software helps to insulate users from the effect of hardware failures. For instance, Exchange’s Active Manager will failover a database to a new server quickly if a disk problem is detected. It will also create a new copy of the failed database using the autoreseed feature if replacement disks are available. Across the entire Office 365 fabric, a CA workflow called “RepairBox” (Figure 1) is constantly monitoring for hardware failures and will open support tickets automatically if an issue is detected like a failed disk. A technician can then replace the failed disk (no attempt is made to fix the disk). The same workflow monitors servers for inconsistencies in their state to detect and fix problems with configurations.
Even with such a sophisticated and smooth-running automatic support infrastructure, Office 365 still runs into some problems. For instance, “stragglers” are servers that run out-of-date software versions that might provide an inconsistent servers to users. Office 365 is in a constant state of server refresh to introduce new software builds that contain new features. As such, with so many servers and so many updates, it can be expected that some updates don’t happen as well as they should, which is the usual reason why a straggler exists.
Standardization doesn’t just apply to server builds within Office 365. Service offerings are standardized in that individual tenants cannot customize the functionality they receive from the service (some element of control is available through the “First Release” option). Support also follows well-laid down paths where problems flow (sometimes more slowly than desired) through first-level phone support eventually to a small group who can actually make a change to a setting that controls how the service operates. Great attention to detail and absolute adherence to procedure are hallmarks of how Office 365 works.

Given that Office 365 is a cloud service, it should come as no surprise that network is its most precious resource. Without sufficient high-quality bandwidth, users will be unable to connect to Office 365, migrations cannot transfer data from on-premises servers, and hybrid connectivity won’t work. Microsoft does not control the network used to connect to Office 365 as this is managed by a large set of Internet Service Providers (ISPs) around the world. Although the Internet was originally designed to survive a nuclear holocaust, local failures caused by cable problems, ISP datacenter issues, and hardware failure can all prevent access to Office 365.
Microsoft can’t control the Internet, but it can take control of its own destiny within the network that connects all of the Office 365 datacenters. That network is dedicated and tightly controlled and monitored. Automatic redundancy is deployed so that a temporary outage is contained and automatically addressed. Everything that can be done to ensure that the service is maintained is done, but even so, like all cloud services, the SLA delivered by Office 365 can only be guaranteed at the boundary of the cloud provider’s datacenters.
With so many servers in use, it should come as no surprise that Office 365 generates a reasonable number of signals relating to server and application operations. Microsoft built a “Data Insights Engine” (Figure 2) using Azure and SQL Azure to process the up to 500 million events generated per hour. The events are aggregated and analyzed to understand how the overall service is operating and to detect problems with individual components.
The general approach is that if a problem is being reported by many entities or different signals, then it must be true. By depending on signals from multiple resources you can get close to 100% fidelity when it comes to the automatic detection of problems, or “Red Alerts” as they are known within Office 365. In addition, by analyzing signals from different sources, Office 365 is able to focus on where the root cause of the problem is likely to be with a high degree of accuracy and this, in turn, allows automatic recovery actions to be launched with a high degree of confidence that they will fix the problem. Taking a data-driven and analytic approach to the detection and resolution of problems is keep to being able to operate at scale.
In addition to its signal processing engine, Office 365 also uses much simpler techniques to know when something might be going wrong. For instance, if a spike in page views occurs for the Service Dashboard, it is likely that customers are checking the dashboard to know whether a problem exists with one of the applications running in the service. Such a spike can often be correlated with an output from the signal processing engine but sometimes it leads to a discovery of a problem that is identified by human beings. The characteristics of that problem can then be captured as a recognizable scenario for future automatic identification and resolution.
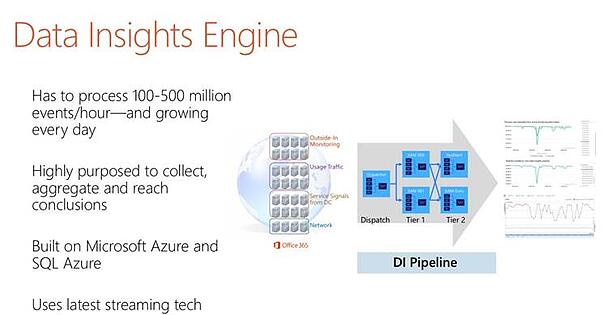
Figure 2: Office 365 Central Admin (source: Microsoft)
On-premises administrators do not have the same levers available to control Exchange but they can apply some of the same basic principles in order to achieve a more reliable service from Exchange. Broadly speaking, most value is gained by focusing on the following areas:
Let’s examine each of these areas in more detail.
It does not make sense to install Exchange in a different way on every server. The general principle is that the configuration and layout of a server should not be so removed from the norm that valuable time is lost if an administrator has to master the details of the environment when a problem occurs. Every company will have different ideas as to how rigid server standardization should be, but here are some ideas to consider.
Table 1 lists some of the areas to consider when designing a standardized approach to server deployment for Exchange 2013.
| Area |
Advice |
|
Operating system |
Install the same software (to build number) on all Exchange servers, including patches and fixes released through Windows Update. |
|
Exchange |
Install the same version of Exchange (including updates) on all servers. Only deploy multi-role servers unless an obvious and well-defined need is identified for a single-role server (such as an Edge server). |
|
Databases |
Within a DAG: Have the same number of copies (at least three) for all databases. Enable circular logging. Keep the transaction logs with their database. |
|
Server-specific settings |
Exchange holds most of its configuration data in Active Directory. Where server-specific configuration files or registry settings are used, care should be taken to ensure that the same values are used on all servers. |
|
Disks |
Have the same number of disks available to all servers. |
|
Other installed software |
Some servers will host specific products (for example, BlackBerry Enterprise Server), but in general it is best if the same tools and add-on products are available on all Exchange servers. |
Table 1: Areas to consider when standardizing server builds
The idea is that all servers designed for a specific purpose (for example, a multi-role Exchange server that is a member of a DAG) are equipped with broadly the same configuration. Computer components change over time as improvements are introduced to the market and it can be impossible to match up everything at a very precise level unless all servers are purchased from the same vendor at the same time. Therefore some difference is acceptable at a detailed level as long as the servers remain broadly the same. For example, it does not matter much if one server uses 4TB disks and another has 6TB disks as long as the same number of disks are available to each server and the software and files are installed in the same locations on all servers. It is more problematic if one server has markedly different performance characteristics than others as in the case when one machine is equipped with more physical CPUs that are faster than available to other computers.
Microsoft has shared details of its cloud server specifications through OpenCompute.org. Going to this level of detail to achieve standard server configurations is only practical when you deal in thousands of servers and can dictate the form factor and design of the desired server. The time then spent in design is more than recouped in time gained through engineering awareness of the common configuration. However, it is possible for much smaller deployments to settle on known server configurations that can be used for applications like Exchange. Having one or two configurations (say, for a medium email server and a large email server) and using them throughout makes the planning, deployment, and management easier than if multiple different types of servers were used.
Going to this level of detail to achieve standard server configurations is only practical when you deal in thousands of servers and can dictate the form factor and design of the desired server.
Note that in some cases you are required to have the same software installed to create a supportable configuration. For instance, all mailbox servers in a DAG must run the same operating system and the same version of Exchange. Ideally speaking, these versions should be as close to identical as possible.
In addition, given that outdated drivers (especially storage drivers) are a major known source of failure on Exchange servers, it makes sense to ensure that all of the hardware drivers used on Exchange servers are up-to-date throughout the organization.
As already mentioned, the advice is to only deploy multi-role Exchange servers. This is actually against the practice in Office 365 where Microsoft use dedicated mailbox and CAS servers. The scale at which Office 365 operates and the management practices used in software deployment (reduce a server to bare metal and reinstall instead of applying patches) makes this example inapplicable to most on-premises environments. Using multi-role servers delivers maximum resilience to the organization, increases flexibility, and makes optimum use of available machine resources. It is also simpler if the same type of server is used everywhere.
Advocates of virtualization will say that deploying virtual Exchange servers is the best approach. This might be true, providing that best practices are followed in the deployment, that a well-defined and obvious business benefit is gained, and that the company has sufficient operational maturity and experience to be able to extract the benefit of virtualization. In other situations, virtualization increases the overhead, cost, and complexity of a deployment and is therefore not aligned with the aim of simplifying the environment.
A vast array of client versions and protocols are available to connect to Exchange. Every client/version/protocol combination increases the complexity of support and introduces new potential for problems after an update to client software or the protocol it uses. A brief list of the potential clients for Exchange 2013 is:
It makes sense to settle on one desktop client and (as allowed by user desire) a reasonable number of client/protocol choices. Mobile device policies can be used to control the versions of Exchange ActiveSync (EAS) clients that can connect so that, for instance, you might only allow Apple devices running iOS 8.1 or above to connect. Protocol settings on the mailbox can be used to restrict access to different protocols.
The potential for error is high every time a human makes a configuration change or performs a management operation on a server. Given
The potential for error is high every time a human makes a configuration change or performs a management operation on a server. This is not because human administrators are stupid. Rather, it is our intelligence that causes us to lose interest in mundane oft-repeated operations, which then leads to mistakes and problems.
All scalable operations focus on eliminating human error through automation. As evident from its use in the product installation procedure, even the most complex Exchange operations can easily be scripted with PowerShell (a script that you can customize to perform an unattended installation of Exchange is available from the Microsoft TechNet Gallery). It makes sense for administrators to script as many common operations as possible so that operations from mailbox provisioning to reporting on database growth are performed in a consistent and predictable manner. It’s true that Exchange administrators are not all PowerShell gurus, but it is also true that many scripts or other snippets of code can be found on web sites that can be repurposed and reused.
The number of events generated by Office 365 is staggering but even a small Exchange installation can produce thousands of events and other signals daily. No human being can make sense of so much data unless they spend an inordinate amount of time checking event logs and other sources to ensure that no out-of-ordinary occurrence goes unnoticed. Given that users expect 24x7 access to email, the task of ensuring that everything runs smoothly is very difficult indeed.
Exchange 2013 helps to resolve some common issues with Managed Availability. Every minute, Managed Availability measures hundreds of health metrics from a server using a comprehensive set of probes, monitors, and responders. Its probes recover information from a variety of sources that are then analyzed by the monitors and, if necessary, a monitor might decide to invoke a responder to resolve an issue. Unfortunately, Managed Availability is a “black box” with no friendly user interface to allow an administrator to interrogate what’s happening on a server. A certain amount of good faith must be attributed that Managed Availability will do the right thing every time.
The evidence from Office 365 is that Managed Availability does a good job. However, Office 365 is a highly standardized and structured environment that is unlikely to resemble your deployment. For this reason, it is wise to regard Managed Availability as just one part in the overall monitoring solution. Depending on your circumstances, you might need additional tools to handle situations such as mobile client management, statistic gathering and reporting (for example, mailbox growth over the last year), number and use of distribution groups, public folder usage, analysis of protocol logs, message tracking reports, and so on.
In fact, given that Office 365 provides its tenants with some nice reports, it is curious that this area is very weak in the on-premises version. PowerShell scripts can help close the gap and many examples of PowerShell-driven reports are available on the web. The scripts used to generate these reports can be altered to customize for your environment.
Monitoring of a hybrid environment is particularly challenging. Data is available from the on-premises side that is unavailable from Office 365. Apart from PowerShell, no APIs are available to interrogate information about service throughput and other statistics. And even if you use PowerShell, Microsoft throttles its use within Office 365, which makes it harder to deal with large collections of objects such as mailboxes. While understandable because they protect the resources necessary to run a multi-tenant service, these restrictions can sometimes be frustrating when outsiders seek to gain an insight into what’s happening inside Office 365.
Office 365 provides a stable and robust service to tens of millions of users daily. It can only achieve this goal because Microsoft has invested heavily to standardize its offerings and implementation, automate its operations, and monitor and understand the signals emitted from the infrastructure.
Smaller companies do not have the resources available to Microsoft, but it is possible to learn from how Microsoft operates Office 365 by introducing similar principles into the operation of on-premises Exchange servers. As always, your knowledge of the company’s operating environment and business goals should guide you in selecting which lessons are appropriate and valuable.
Going Hybrid or already in the Cloud? Check out the Reporting & Monitoring Hybrid Management Tool – Mailscape for Exchange Online.



