On December 3, Microsoft had an outage that affected their Office 365 service for customers in most of Europe. More precisely, the outage was actually in Azure Active Directory.
What happened?
Customers started reporting an outage shortly before 9am UTC on 3 December. As is typical of cloud service outages, there was a swell of traffic on Twitter reporting problems with individual tenants before Microsoft formally updated its service health information to reflect that they knew of the outage.
The advisory note on Microsoft’s Azure service health dashboard had this to say:
SUMMARY OF IMPACT: Between approximately 09:00 and 13:15 on 3rd Dec 2015 UTC, customers experienced intermittent issues accessing Azure services that use, or have dependencies on, Azure Active Directory. A full list of services reporting downstream impact is listed below this message in the History tab of the Service Health Dashboard. While impact was centralized to West Europe and North Europe, customers outside of these regions may have experienced issues as a result of configurations specific to their individual scenarios. PRELIMINARY ROOT CAUSE: A configuration error led to incorrect routing of production traffic. This resulted in the inability to access services dependent on Azure Active Directory authentication and services...
From this description, we can reach some very interesting conclusions. First, this appears to have been a people problem, not a flaw in the software itself. We may never find out exactly what “configuration error” means in this case, but it seems safe to say that some busy engineer made a mistake that was quickly propagated through Microsoft’s European data centers. As Exchange MVP Ed Crowley famously said, there are seldom good technical solutions for behavioral problems; it’s hard to completely eliminate the ability of trusted administrators to accidentally do stupid things. As time passes, I expect that a larger share of Office 365 and Azure outages will be due to human error than to faulty software or data center failures.
Second, the four-hour length of this outage seems right about average. For example, the November 26th Azure storage outage in the US-West region lasted a bit over four hours. However, if you spend a few minutes and take a quick look at the last 90 days of reported Azure problems and you’ll notice that there are more of these small outages, spread across more services and regions, than you might suspect. This lines up with Tony Redmond’s assertion that an impressive 99.99% SLA claim loses much of its shine when that percentage is applied to tens of millions of users.
Noticing the outage
Third, one of the affected services was the Office 365 service health dashboard itself! This leads to an unpleasant Catch-22: you think Office 365 services might be down, but you can’t log in to the Office 365 service health dashboard to check. Worse, in this case, some services worked (such as desktop Outlook on existing sessions), while others (namely, anything that depended on opening a new authentication session, including remote PowerShell, Outlook on the web, and SharePoint Online) did not.
One of the key design principles behind our Mailscape 365 product is that we don’t depend on any single test to tell you whether your Office 365 service is healthy or not. This is one of the primary reasons Gartner recently recommended Mailscape 365 in their "10 Steps to Develop a Practical Network Performance Strategy for Office 365" research note. Instead, we generate synthetic transactions that faithfully imitate what clients actually do, including logging on directly (and through AD FS if you’re using it), sending Exchange ActiveSync requests, and so on. Instead of authenticating once and using that authentication token for all tests, we authenticate separately for each of the synthetic transaction categories that we perform. When Azure AD failed, the synthetic transactions we use to test Exchange Active Sync, Autodiscover, Outlook Anywhere, MAPI/HTTP, mail flow, SharePoint upload/download, PowerShell, and subscription/license tests all failed too, and we reported those failures in real time to our customers in the affected region.
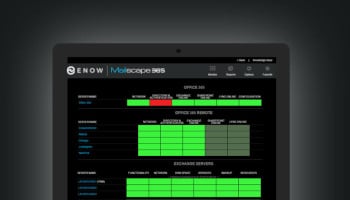
Of course, our customers outside the affected region also benefited—they could clearly see from the dashboard that their own tenants weren’t affected. Getting a quick summary indicating whether or not you have anything to worry about is a great time- and worry-saver.
What this all means
We live in a complex, interconnected world. In particular, Azure and Office 365 are extremely complex systems. Pinpointing the cause of this sort of outage reminds me of the lengthy investigative process that takes place after a commercial airplane crashes. While it might be easy to quickly find a credible root cause, the initial reports often lack depth, so it’s usually worth waiting for a detailed analysis to highlight exactly what happened, why it happened, and how it can be prevented. However, having that detailed analysis is only useful after the fact—in the moment, you need an immediate read on whether the services you depend on are working or not, and Mailscape 365 gives you that in a clear, immediately digestible format. (And if you think that’s cool, wait until you see what we’re working on next….)